Background
Satellite imagery is ...
Satellite imagery has become inextricably intertwined with our lives, especially in first-world countries as we leverage it for many key functions in life such as GPS navigation.
But what about countries that are less technologically advanced and require extra assistance in mapping out their roads?
Problem Statement
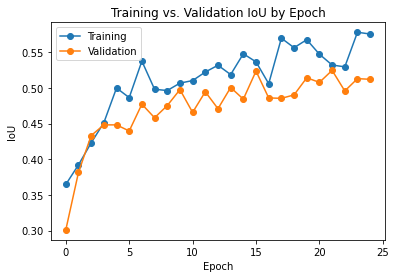
Road segmentation is ...
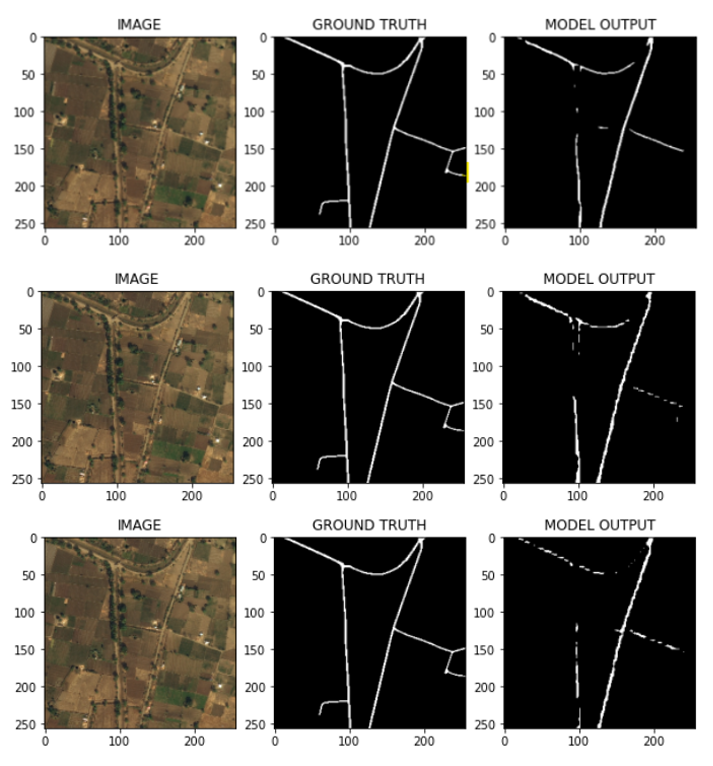
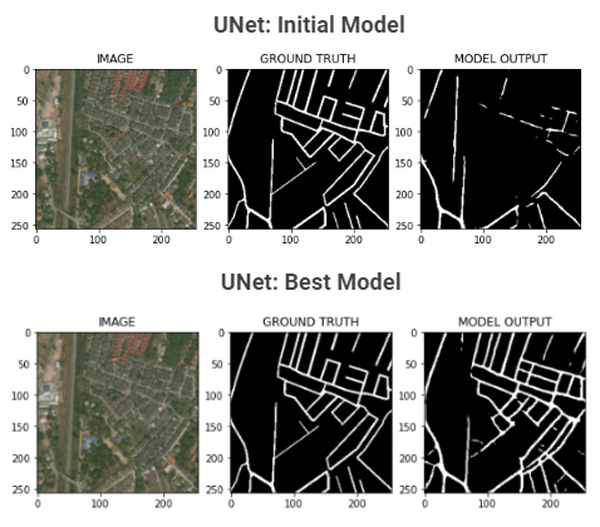
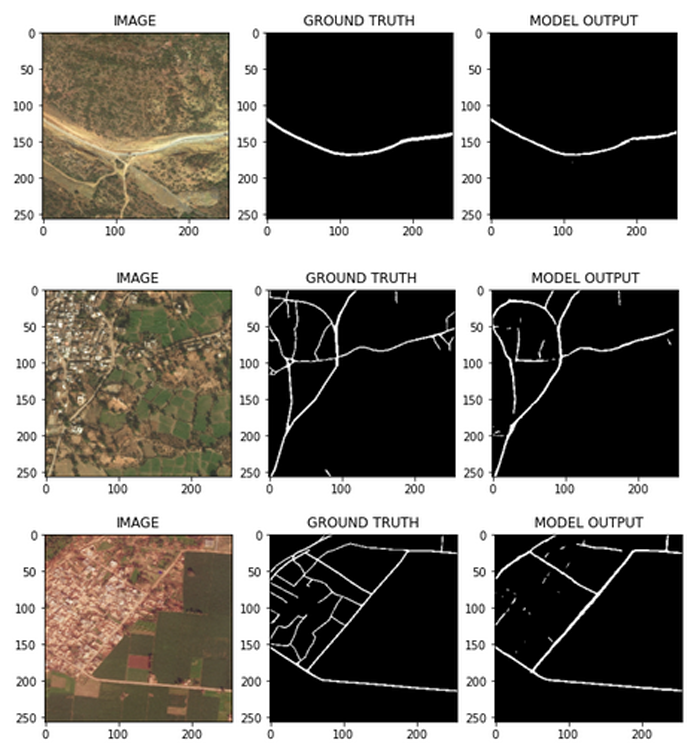
Segmentation is where we separate and cluster elements of importance from an image. Another name for this is pixel-level classification - where we assign labels to all pixels present in the image. In our case, we will only be needing to identify proper roads from mud roads, flat expanses, and the like, then drawing out the roads.
In many developing countries, roads are not easily accessible or recognizable. Maps are also hard to find and this limitation can affect response activities during natural disasters.
We built a road segmentation model that will help assist in predicting roads from satellite imagery. The intent is for non-profits and rescue teams to use this model to identify roads and provide rescue teams with access to data so they can reach populations in need.